
TEXT MINING - DATA
AI ART - ART
DECISION TREES
This is the first part of the mod 3 text mining project assignment, exploring machine learning models and their applications to my AI/Art Text Data.

DECISION TREES
Decision trees are yet another supervised learning model. I’m using the same data as previous, because I trust that one to already be cleaned and well structured. Plus, using the same data lets me directly compare the performance of different models.
Decision trees are quite different from NB, though both are used for classification. While both decision trees and Naïve Bayes are used for classification, decision trees work quite differently. In this model, each internal “node” chooses a feature (a word, in my case) and evaluates a threshold that best splits the data into either class (my classes are the labels, “AI Art” and “Art”).
(ex: if the threshold for “Stable Diffusion” is a freq. of 2, documents mentioning it three times go one way, and those mentioning it two or fewer times go the other, except more funky and nuanced because my dataset doesn’t contain such simple identifying keywords!).


I iterated quite a bit on different settings to make the decision tree more legible — stuff like setting a depth limit and adjusting the minimum samples needed to make new leaves. After a few rounds of messing with values manually, I went back to the old reliable: Grid Search. Basically, Grid Search tries every possible combo of the parameters you give it, and then checks which one performs best using cross-validation. I had it plot the results in a heatmap so I could actually see where the accuracy peaked. The most important bit is the line printed at the bottom — it tells me exactly which params to use to get the highest accuracy


The earlier iterations already told us so: but the model caps out at about 67% overall accuracy. This is just a limited set so that the tree becomes legible. Visiting the confusion matrix, we can see it correctly flags 80 of 100 true AIart posts (80% recall) but with only 66% precision, meaning roughly one‐third of its “AIart” predictions are actually incorrectly labeled, and are in truth general art discussions. Its comparatively worse labelling art: 70% of its “art” calls are right (precision) but it only catches 53% of true art samples (recall). That means nearly nearly half of those art discussions are just completely slipping through as false positives for AIart. You can imagine them being passed through each conditional node and them making it to the end and being labelled “AiArt” discussion.



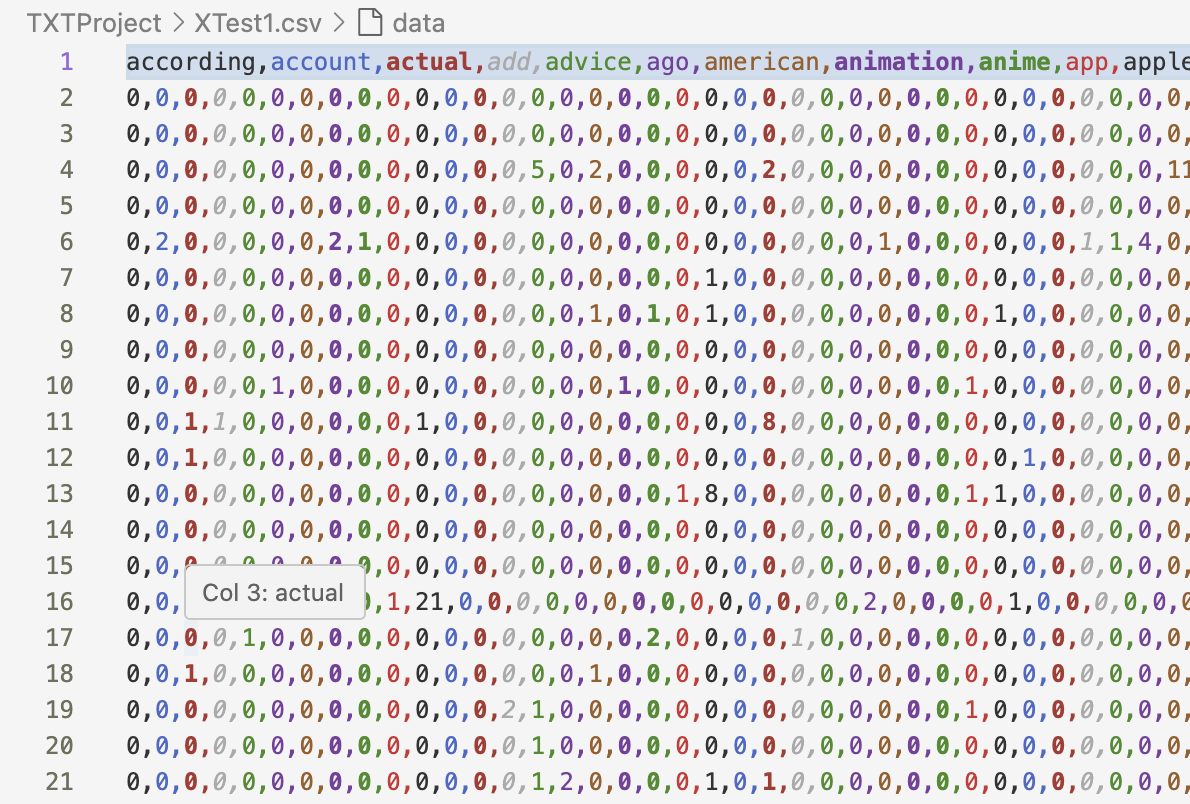
This is the training and testing data as used for NB. Its just a sample from the same original dataset when it split into two separate, non-overlapping groups (70:30 test:train). It’s important to note that the training and test sets are completely disjoint—they have nothing in common.
If you trained a model and then “tested” it on the same data it was trained on, it wouldn’t prove anything meaningful. During training, the model is shown both the inputs and the correct labels—so testing it on the same examples just confirms it memorized them, not that it can generalize to new data. (also why it needs to be labelled data: labeling is fundamental to how supervised models train.)



This is the initial attempt. It has an accuracy of 69% — meaning it correctly identified 129 the 187 test samples. other data like the recall and precision tell us how many of the true cases the model correctly identifies, and how much of the time it’s correct. In this model, the labels have a mismatched breakdown:
“AIart”: higher recall (75%) but lower precision (64%).
“aiArt”: higher precision (74%) but lower recall (64%).
Reading the confusion matrix, we see that this model has 22 errors where art is labelled AI Art, and 36 cases where AiArt conversations are labeled art.
When the tree looks like this, its a pretty good indication that the model is overfitting.



These decision trees can help me classify whether a given piece of text belongs to a discussion about AI art or human-made art. The goal is to see which words, or combinations of word frequencies, the model uses to split the data and make its predictions. This will directly identify, as far as my data goes, which terms are most indicative of each community and how structured or diffuse the language is across them.
The more accurate my decision tree is at separating the two classes of text data, the more I can identify what terms are most indicative of each community and how similar or dissimilar the language is across the label boundary.
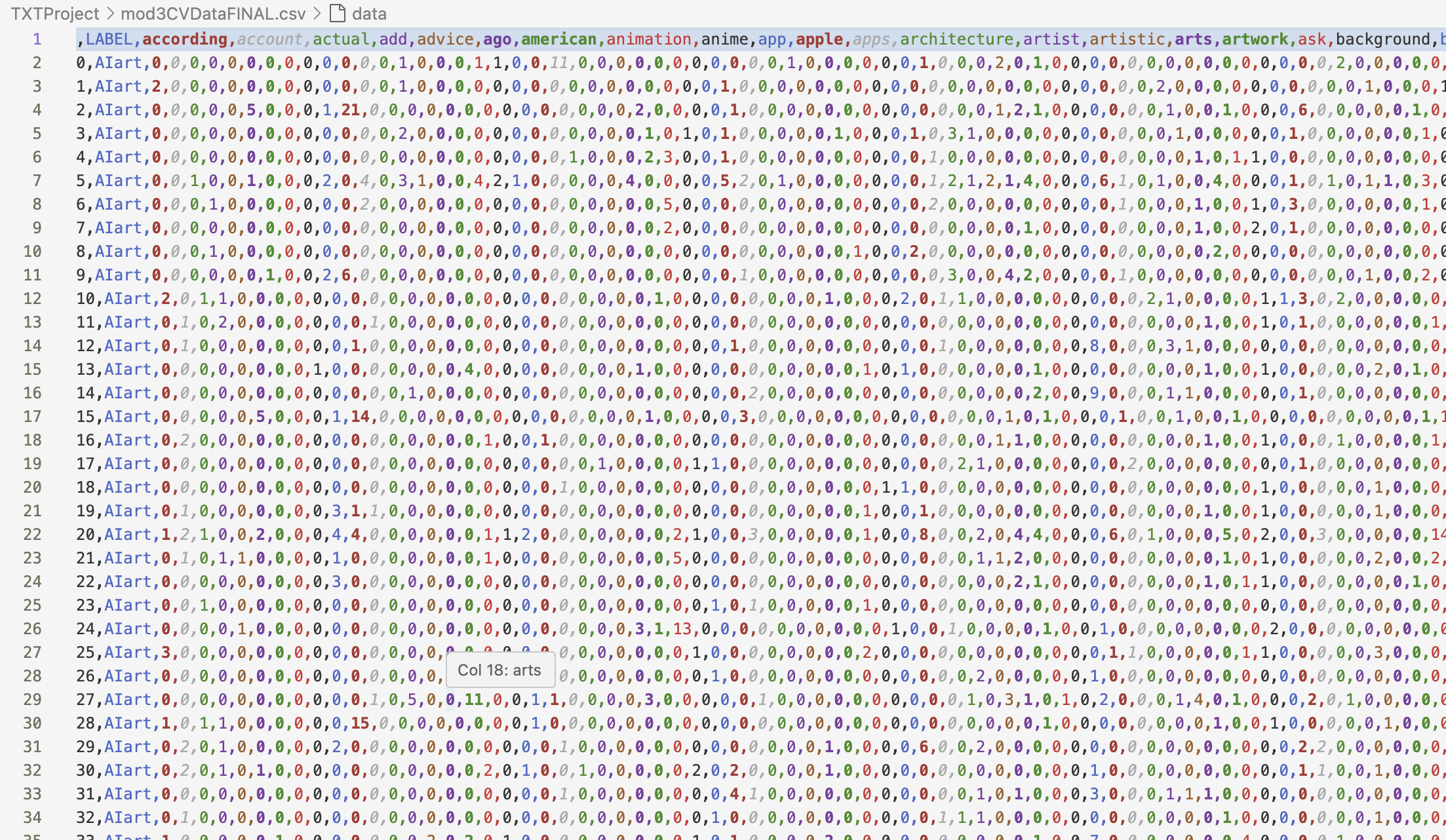
To review: this dataset has been sourced from RedditAPI and NewsAPI: searching for “AI Art” and “Art” news articles, and posts and comments from Art and AI Art subreddits. This data has been cleaned, combined, and count vectorized with the settings to the right. This final dataset is linked below.

Despite the low accuracy, Decision trees can tell us some interesting things about our data. the top splits are things like “generated,” “museum,” “tablet,” “professional,” and “matter”, while more general words in the data like “Painting,” “gallery,” “illustration,” “technique” are too nuanced, not identifying either discussion either way. The value in exploring these decision trees isnt the resulting models, but the way it breaks down the keywords and makes me brainstorm what kinds of discussions are ‘identifying’ and ‘not identifying enough’ that could be happening on both sides of the AI / AI Art Divide.